1. Introduction
There are different diseases affecting public health and safety across different parts of the world. Much research has centered on proffering solutions by diagnosing and truncating the transmission of diseases such as COVID-19 (henceforth, SARS-CoV-2) [
1,
2], HIV [
3,
4], Ebola [
5,
6,
7,
8], malaria [
9,
10,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20], hereditary diseases [
21,
22], monkeypox [
23,
24,
25], tuberculosis [
26,
27,
28,
29,
30], and other diseases [
31,
32,
33,
34,
35], by adopting different computational, modeling and bioinformatics approaches. Recently, the World Health Organization (WHO) declared monkeypox disease a case of a global public health emergency of International Concern [
36]. Health medications such as vaccines, and liquid and solid medications are very essential and in high demand to combat the diseases [
37,
38,
39,
40]. After the production of these medications, one of the major problems is how to transport and distribute these health medications effectively and efficiently to regions where they are urgently needed. Health medications form an essential part of human society. However, the supply chain process that health medication undergoes before they are safely delivered to their various destinations can be very complicated and challenging. Issues such as unpredictability, instability, and a lack of accountability are problems facing the global supply chain sector. Companies today, (pharmaceutical firms inclusive), face a distinct set of difficulties, including transportation issues, outsourcing, bottlenecks due to unexpectedly high demand, in addition to growing consumer expectations, and complicated operational processes. Health medication supply chain fragility was recently brought to light by the outbreak of the SARS-CoV-2 pandemic [
41,
42].
At present, organizations are seeking ways to make their supply chains less susceptible to disturbances in the current environment of transforming the supply chain competitive landscape, evolving workplace practices, and increasingly volatile demand [
43]. Many well-known and new supply chain difficulties can be solved by computational approaches such as machine learning. Artificial intelligence helps companies manage their supply chains better and make them more resilient to disturbances. One of the ways supply chain managers can take to address pressing challenges in the supply chain process is to use machine learning use cases as a prepared roadmap of the steps they should follow [
44,
45,
46].
Recently, the conventional linear supply chain has been evolving over the past few years into a computerized supply chain network, which we have all seen (DSNs). Businesses are actively reviewing their overall supply chain strategy in anticipation of the recent reality, and COVID-19 has only expedited this process [
47]. It is feasible to convert conventional, linear supply chains into linked, adaptive, expandable, and configurable digitized supply chain networks with the aid of technologies like IoT, intelligent systems, and deep learning. Conventional supply chains operate according to a predetermined workflow. This is how most industrial execution systems work [
48]. A nondeterministic system, on the other hand, lacks predetermined workflows and gives automation itself some latitude in how it manages business logic. Improved online manufacturing systems can reorganize and improve production processes, prevent service disruptions, and lower the expenses associated with changing product lines [
49].
The widespread use of machine learning throughout the supply chain has made it possible for retailers, suppliers, and wholesalers to implement the massive adjustments that are urgently required to address the epidemic. Benefits that have never been feasible before are now available to supply chain operations thanks to machine learning, including cost savings via improved supply chain prediction and risk management, rapid supplies, and improved customer experience, to mention a few [
50]. Machine learning will most significantly aid supply chain experts by giving them additional insight into how to improve supply chain efficiency and foresee abnormalities in logistics costs and performance before they arise. Machine learning is also revealing which areas of automation will result in the greatest scale advantage. As a result of supply management machine learning technologies, retailers and suppliers are cooperating in whole new ways. Machine learning, a branch of artificial intelligence, uses data to train computer models to respond to events on their own [
51]. The computer may progressively train itself in this way, improving the precision of its own algorithms. Some machine learning methods are used in the supply chain. According to Gartner [
43,
52], by 2023, cognitive algorithms and artificial intelligence approaches will be implemented or augmented in 25 percent of all supply chain technology systems, according to Gartner [
43,
53].
Inventory management is one component of supply chain management. It requires expensive storage and upkeep of inventory to keep it in good shape. Therefore, inventory planning should be approached carefully by supply chain managers as it directly affects a company’s cash flow and profit margins. Among the most prevalent applications of machine learning in the supply chain is inventory management [
54]. The issue of under-or overstocking can be resolved with the aid of machine learning. With ML, you can forecast the growth in demand based on data that can be gathered from a variety of sources, such as the open market environment, trends in the market, advertising, purchases, and historical analyses [
55]. Additionally, you can plan to stock up on supplies and avoid having an excess of either items or crucial components for manufacture. There is a need for a variety of facts for the forecast to be correct. Machine learning presents a range of solutions to the issue of inadequate data for research to be successful. One such method is data augmentation, which enables you to greatly enhance the variety of data provided for training models without having to collect additional data. Depending on the type of data, several augmentation strategies are utilized in deep learning applications [
56,
57]. Approaches like Synthetic Minority Over-sampling TEchnique (SMOTE) or Synthetic Minority Over-sampling TEchnique-Nominal Continuous (SMOTE NC) are frequently used to enhance plain numerical data [
58,
59]. Depending on the nature of the project, augmentation techniques for large amounts of data, such as images and text, range from straightforward manipulations to neural network-generated data. A machine learning technique called incremental learning trains a model using a small quantity of data [
60]. Rather, learning begins with a rather basic model that generally forecasts the estimated value with a certain variability. The model is trained to be able to predict outcomes more accurately when a data scientist inserts additional data instances. The number of datasets will eventually be sufficient to generate accurate predictions.
Along with supervised learning and unsupervised learning, reinforcement learning (RL) is one of the three fundamental machine learning methods. It employs rewards and penalties as cues for appropriate and inappropriate conduct [
61]. RL is employed in robotic systems and process control to allow the robot to develop an effective, adaptable control system for itself that gains knowledge from its own experience and behavior [
62]. When it comes to data, the decision of whether to employ a data lake or a data warehouse emerges. Data lakes are frequently employed in advanced analytics or machine learning applications. They are frequently employed in ML projects because they enable the real-time collection and storage of data from numerous sources. A data warehouse is appropriate for operational processes and daily operations, whereas a data lake is ideal for those who require a thorough study of broad-spectrum data that have been acquired over time. Nevertheless, a lot of businesses are increasingly utilizing both types of storage, particularly when a data lake serves as the foundation for a data warehouse that leverages sanitized and structured data from a DL [
63].
Another type of supply chain ML application is computer vision (CV) for inventory control. It is often used in many different settings. It is first used to categorize and tally freshly delivered items. CV also helps in the identification of visible package damage. With the use of computer vision, the program can classify the items it “sees.” Robots equipped with cameras, for example, may scan your storage spaces and instantly produce a picture of your goods. Machine learning techniques that may be applied in the CV sector include supervised learning, unsupervised learning, and reinforcement learning [
64].
Predictive maintenance of equipment is another common application of machine learning in the supply chain. Based on real-time asset data instead of a predetermined timetable, ML ensures reactive and preventative maintenance of equipment. Supply chain experts can drastically reduce maintenance costs by improving asset upkeep. Additionally, ML aids in the decline of no-fault-found (NFF) situations. When a unit is deemed to be defective, it is taken out of service and designated as NFF. If no abnormality is found, the device is put back into use without any repairs. The production process becomes more efficient as the number of such accidents decreases [
65]. ML aids in determining a package’s location throughout the logistics process. It enables supply chain experts to monitor the whereabouts of cargo while it is being transported. Additionally, it gives insight into the circumstances of the package’s transportation. Retailers can keep an eye on variables like temperature, vibration, humidity, etc. with the use of sensors. Additionally, ML supports in-the-moment route optimization. It keeps track of the weather and the state of the roads and makes suggestions on how to shorten travel time and optimize the route. This allows for the diversion of trucks at any moment when a more economical route is available [
66].
Machine learning is utilized in warehouses to automate manual tasks, foresee potential problems, and minimize paperwork for warehouse workers. For instance, computer vision enables the management of conveyor belt operations and the forecasting of blockages. Thanks to NLP and OCR [
67], warehouse personnel can automatically recognize goods’ arrival and modify their delivery statuses. On the product, barcodes and inscriptions are scanned by cameras, and the data are immediately input into the system. Additionally, machine learning assists in programming robots and autonomous vehicles, both of which are commonly utilized in warehouses. Autonomous vehicles and robots assist with receiving, packing and unpacking, transporting, and uploading and unloading boxes with the use of system-integrated instructions. In this scenario, computer vision aids in locating a vacant space for a box, monitoring its proper placement, and preventing robot and automobile accidents in warehouses [
68]. This paper is an innovative work because it deals with the hybridization of deep learning and Bayesian optimization with a tree parzen estimator for the classification of the supply chain of health medication datasets. To the best of our knowledge, there is no study in the literature that has adopted such a technique. The major contributions of this work include:
A survey of machine learning and deep learning algorithms that have been applied for supply chain management was presented.
Determination of the most appropriate deep learning model for the classification of supply chain health medications was done.
Development of deep learning and Bayesian optimization Techniques with Tree Parzen Estimator for classification of supply chain health medications was done.
Evaluation of the performance of the proposed methods for classifying health medications using different metrics was achieved.
The rest of the paper is organized as follows: a review of related work together with the summary of contributions table is presented in
Section 2. Whereas
Section 3 explains the methods used for the classification of supply chain health medications. The simulation and statistical results of our experiments are presented in
Section 4. The conclusion of the paper is in
Section 5.
3. Model Specification
We compared the performance of two widely used deep learning techniques. In this case, we contrasted a one-dimensional convolutional neural network with long short-term memory (LSTM) (1D-CNN). Deep learning or deep structured learning refers to neural network types with many layers, such as LSTM or 1D-CNN. When it comes to recalling information from prior occurrences, these networks perform better than normal neural networks. The network’s closed-loop design keeps the information safe. Every network in the loop gets input and data from the preceding network, performs the specified action, and then outputs data while sending them to the next network. While some applications just require the most recent data, others may call for more historical data. Such examples can be learned by Recurrent Neural Networks (RNNs), specifically Long Short-Term Memory (LSTM) Networks [
86]. These networks are specially designed to circumvent the recurrent networks’ issue with long-term dependency. Long-term memory systems (LSTMs) are effective in recalling information. The validity of the model may be impacted by extra previous information; hence LSTMs are an obvious option for usage. The LSTM block contains four gates: cell state gate retains
information over time, forget gate
regulates the extent of the value maintained in the cell, input gate
controls the extent of the value flow in the cell, and the output gate
controls the extent of the value in the cell to be utilized for computing the output. A completely linked layer and an activation function are included in each gate. The LSTM block also has three inputs: cell state
; previously hidden state
; and current input
, as well as three outputs: cell state
; hidden state
; and current output
. The current output is created depending on the hidden state. The mathematical formulation of the LSTM units is as follows:
A unified neural network of 1D-CNN, on the other hand, is made up of 12 layers: five 1D convolutional neural network (1D-CNN) layers, two dropout layers, one max-pooling layer, one flattened layer, and three fully connected layers. The signals are first routed via the first convolutional layer, which has a filter size of 32. The kernel of the first layer of our proposed 1D-Convolutional network is set to 3, indicating that all weights will be shared by every stride of the signal’s input and output layers. The filter size is raised from 32 to 64 in the second 1D-convolutional layer, and the kernel size is adjusted to 3 in all 1D convolutional layers. Furthermore, the filter size is set to 128 in the third 1D-convolutional layer, but the padding is set to the same value in all three 1D-convolutional layers. The fourth layer is a max pooling layer that is used to down-sample the input representation from layer three. The pooling size is set to 3, the strides are set to 2, and the padding is set to the same. The fifth and seventh convolutional layer filter sizes are increased to 256 and 512, respectively, with the same padding and kernel size set to 3. The sixth and eighth layers are dropout layers with a value of 0.2 that are positioned between the fifth and sixth convolutional layers to reduce overfitting. The ninth layer is a flattening layer that reduces the input data to a single dimension. The flatten layer’s single dimension was fed into the fully connected layer 10 with 512 nodes, and the leaky ReLU activation function was employed in all activation functions. Layer 11 has 256 nodes and is completely connected. After passing through Layer 11, data are delivered into the last fully linked layers with a linear activation function for final prediction.
Figure 2 is the block diagram of the proposed model. The mathematical expressions for the 1D-convolutional neural network (
), Leaky ReLU activation (
), max pooling
), and dropout (
) layers are as follows:
3.1. Repeated k-Fold Cross Validation
To improve the predicted performance of deep learning [
87,
88] models, repeated k-fold is utilized in this study. As for regression and classification models, it may be used for both [
89,
90,
91,
92]. Provide the mean result across all folds from all runs by simply iterating the k fold cross-validation approach several times. The supplied dataset will be divided into k folds according to the first input k, which is specified to be 5 (or subsets). On the k-1 subsets, the model is trained, and its performance is assessed using the remaining subset. These stages will be repeated up to a limit of two times, which will be determined by the algorithm’s second parameter. Each iteration of the repeated k-fold cross-validation is a conventional k-fold algorithm implementation. To begin, the dataset is divided into k subsets, each of which is randomly assigned a number between 1 and 5. The subset is used as a validation set, with the remaining subsets being used for training. On the validation or test set, the model is trained and assessed. The prediction error is also determined, and the step is performed k times. Finally, the total prediction error is calculated by averaging the prediction errors in each scenario.
3.2. Other Related Works
Chen et al. [
93] proposed a new disease diagnosis and treatment recommendation system to make the best use of the sophisticated medical equipment found in modern hospitals and the depth of expertise of skilled physicians. First, a Density-Peaked Clustering Analysis (DPCA) technique for illness-symptom clustering is proposed in order to more precisely and effectively identify disease symptoms. Additionally, the Apriori algorithm does association studies on disease-diagnosis (D-D) rules and disease-treatment (D-T) rules independently. Even if they are in a constrained therapeutic setting, patients and novice doctors are advised to receive the proper diagnosis and treatment plan. A parallel solution was also implemented using the Apache Spark cloud platform in order to achieve the objectives of high throughput and low response latency. Comprehensive experimental results show that the proposed system efficiently achieves illness-symptom clustering and provides intelligent and precise disease treatment suggestions. The proposed system’s weakness is the lack of evaluation of the efficiency of disease diagnostic and treatment methods.
Wang et al. [
94] developed a novel system for solving the problem of incremental group-level popularity prediction. The two key phases are restarting CP decomposition to reduce cumulative error and progressively forecasting by utilizing progressive CP decomposition. In terms of forecast accuracy and running time, extensive empirical studies show that IGPP performs better than other baselines. The study concentrated mostly on investigating dynamic diffusion throughout the temporal dimension. The authors also expanded the applications of our incremental methodology in big data environments and explored more general incremental approaches that can describe the evolving groups over time.
Chen et al. [
95] applied a Periodicity-based Parallel Time Series Prediction (PPTSP) technique for large-scale time-series data that is suggested and implemented in the Apache Spark cloud computing environment. A Time Series Data Compression and Abstraction (TSDCA) approach is described to efficiently manage the enormous historical datasets. This algorithm can scale down the data while properly retrieving the features. On the basis of this, they suggested a Multi-layer Time Series Periodic Pattern Recognition (MTSPPR) algorithm employing the Fourier Spectrum Analysis (FSA) technique. A Periodicity-based Time Series Prediction (PTSP) algorithm is also suggested. The models for all prior periods are used to forecast data for the later period, and a temporal attenuation factor is added to reduce the influence of the various periods on the outcome of the prediction. Additionally, they developed a parallel approach on the Apache Spark platform, utilizing the Streaming real-time computing module, to enhance the performance of the suggested algorithms. Extended experimental results demonstrate that, in terms of prediction accuracy and performance, the PPTSP approach has a significant edge over competing algorithms.
Pu et al. [
96] developed a new attention convolution neural network (named ED-ACNN) for anticipating the movement of people in every area of a city center, using historical human traffic data, and it is based on an encoder-decoder architecture. The proposed system is capable of learning all the spatial and temporal interrelations of vehicular images, including proximity, period, and pattern. The effectiveness of the method was assessed using three different real-world datasets from Beijing and New York City. It outperformed ten widely used baselines in terms of accuracy and efficiency, proving that the suggested approach is more suitable for predicting traffic flow. Experimentally, Beijing and New York City’s two distinct forms of population flow were thoroughly evaluated, and the findings demonstrate that the suggested approach can be highly competitive with leading-edge thresholds.
Fillipe et al. [
97] applied long short-term memory (LSTM) as a model for forecasting time series. The model focused on a large volume of data from a time series characterized by nonlinearities. However, Oyewola et al. [
98] developed a novel Auditory Algorithm, which follows the pathway of the auditory system like that of the human ear. The results show that the auditory algorithm preforms better than other algorithms considered in the paper.
4. Results and Discussion
In this section, the dataset and developed models such as the Long Short-Term Memory (LSTM) and One Dimensional Convolutional Neural Network (1D-CNN) were subjected to repeated K fold cross-validation. Python 3.6, numpy, sklearn, keras, imblearn, pandas, matplotlib, seaborn, and plotly are the python packages used in this work. The hyperopt library in Python is used to perform Bayesian hyperparameter optimization. The supply chain dataset’s missing values were shown using a heatmap. The heatmap in
Figure 3 shows two colors: red for missing data and green for remaining values with no Nan values. Shipment Mode, Dosage, and Line-Item Insurance contain missing values.
Correlation heatmaps are heatmaps that display the degree of correlations between numerical variables. The links between variables and their strength are visualized using correlation graphs. Every numerical variable in a correlation plot is typically represented by a column. The rows reflect the connections between each pair of variables. The values in the cells represent the strength of the correlation; positive values represent a positive relationship, while negative values represent a negative association. The strength of potential relationships between variables may be evaluated using heatmaps of correlation. Additionally, linear, and nonlinear correlations, as well as outliers, may be found using correlation plots. It is easy to quickly spot relationships between variables because of the color coding of the cells. Correlation heatmaps may be used to discover both linear and nonlinear relationships between data. Line-Item Quantity is substantially connected with Line-Item Insurance, as seen in
Figure 4, with a correlation value of 0.8. Meanwhile, the Pack Price has a 0.6 correlation coefficient with Unit Price, although Unit Price is unaffected by Unit of Measure or ID.
The data peaks are displayed using a violin plot, which is a mix between a box plot and a kernel density plot. It serves as a representation of the distribution of numerical data. Violin plots display summary statistics as well as the density of each variable, as opposed to box plots, which can only offer summary statistics. The median can be seen as a white dot in violin plots. Conversely, the narrow gray line represents the remaining portion of the distribution, while the wide gray bar in the middle displays the interquartile range. On either side of the gray line, a kernel density estimation is displayed to demonstrate how the data are distributed. The violin plot is divided between broader and skinnier parts, with wider areas representing a greater likelihood that members of the population would adopt the given value and skinnier areas representing a lower probability. As seen in
Figure 5, the median Pack Price for Pediatric and Adult is about 1 but with a greater likelihood, whereas the median Pack Price for ACT is around 45 but with a lower chance. Furthermore, with a decreased chance, the median Pack Price for Malaria is about 30.
The performance of the deep learning models used in this study was enhanced with the aid of repeated k-fold cross-validation. This merely involves repeating the cross-validation process and reporting the average outcome across all folds from all runs. The supply chain shipping data are separated into five folds and repeated twice in this approach, as shown in
Table 1,
Table 2,
Table 3,
Table 4,
Table 5 and
Table 6. When training our models, we must consider loss and accuracy. Loss is a metric that represents the sum of our model’s errors. It determines how well or poorly our model is performing. Furthermore, accuracy assesses how well our model predicts by comparing model predictions to true values in percentage terms.
Table 1 displays the Loss and Accuracy of Long Short-Term Memory (LSTM). The Loss is within the range of 1.3907 and 1.4682, which means that the model does not perform well. Also, the accuracy in
Table 1 is within the range of 50 and 55 which shows that the accuracy is low. Since the loss is low and accuracy is low, it means the LSTM model is not performing well.
Table 2 displays the Loss and Accuracy of the One-Dimensional Convolutional Neural Network (1D-CNN). The Loss is within the range of 1.3 and 1.4 while the accuracy is within the range of 52 and 55. Both the loss and accuracy were very low. It means that 1D-CNN is not performing well.
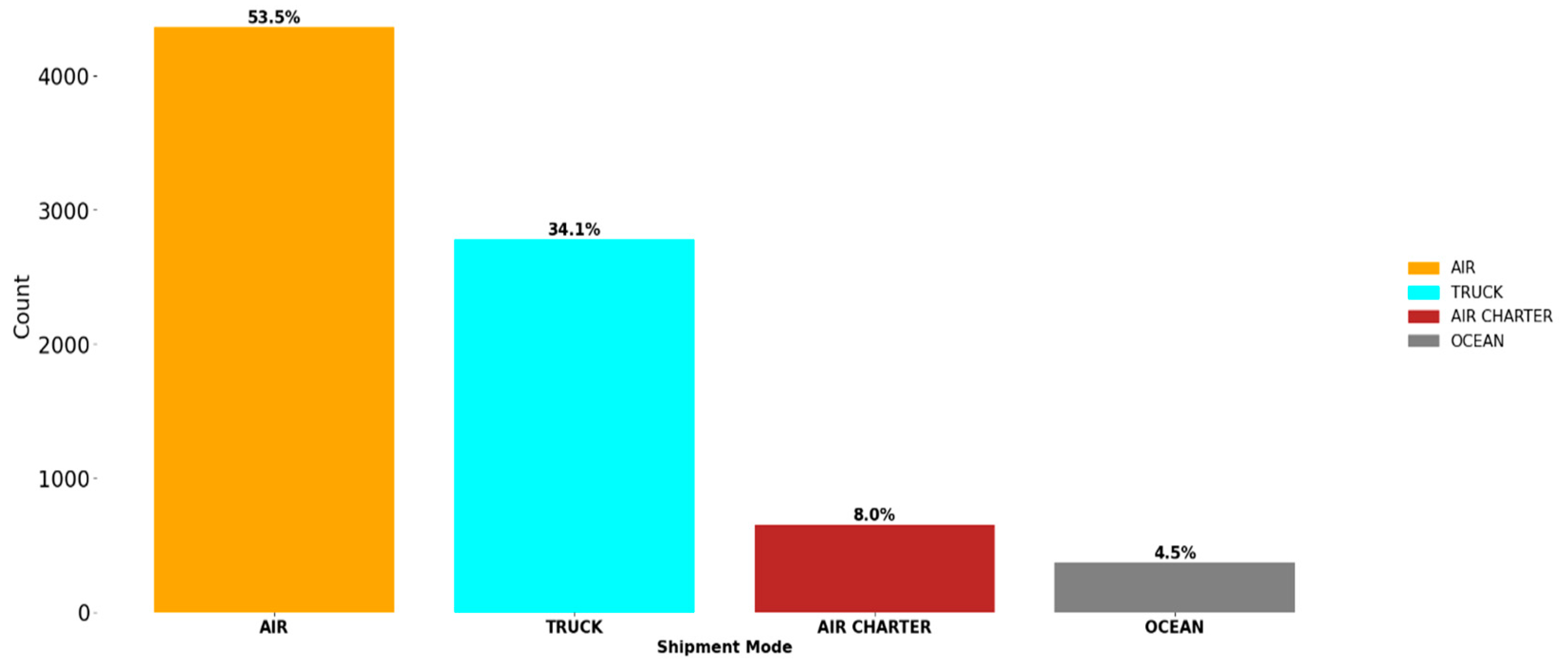
By keeping all the data from the minority class and lowering the size of the majority class, under-sampling is a method for balancing disparate datasets. As demonstrated in
Figure 1, there were uneven classes in target variables such as shipment mode. The dataset was undersampled using AllkNN. The Loss and Accuracy of LSTM and 1D-CNN with AllKNN are shown in
Table 3 and
Table 4. The accuracy of LSTM has increased from 50% to 63%, indicating that the model outperforms the prior model. To fine-tune the deep learning methods in
Table 3 and
Table 4, Bayesian Optimization (BO) using a tree-structured parzen estimator was used. Bayesian Optimization is a method for finding the lowest or maximum of an objective function that uses the Bayes Theorem to guide the search. In many real-world analytics applications, optimizing a function is critical. By optimization, we imply determining the objective function maximum or minimum with a certain set of parameter combinations.
Table 5 and
Table 6 show the outcomes of hyperparameter adjustment for LSTM+AllkNN and 1D-CNN+AllkNN.
Table 5 and
Table 6 show a slight improvement in accuracy, indicating that the accuracy is performing well.
Table 7 shows all of the parameters used in LSTM+AllkNN and 1D-CNN+AllkNN before and after Bayesian Optimization using the Tree Parzen estimator in LSTM+AllkNN and 1D-CNN+AllkNN, respectively. After using Bayesian Optimization, there is a modest rise in the parameter. The pie chart of the overall Loss of LSTM, 1D-CNN, LSTM+AllkNN, 1D-CNN+AllkNN, LSTM+AllkNN+BO, 1D-CNN+AllkNN+BO is shown in
Figure 5. 1D-CNN+AllkNN has a relatively low percentage loss compared to other models, indicating that the model outperforms the others. Furthermore,
Figure 6 depicts the pie chart of the overall loss of LSTM, 1D-CNN, LSTM+AllkNN, 1D-CNN+AllkNN, LSTM+AllkNN+BO, and 1D-CNN+AllkNN+BO. The results show that 1D-CNN+AllkNN+BO has the lowest loss with 15.3% while LSTM and 1D-CNN have the highest loss with 18.3%.
Figure 7 depicts the overall accuracy of LSTM, 1D-CNN, LSTM+AllkNN, 1D-CNN+AllkNN, LSTM+AllkNN+BO, and 1D-CNN+AllkNN+BO. The ranking is topped by 1D-CNN+AllkNN, which has an extremely high accuracy of 17.6 percent. This means that the model performs admirably in supply chain management.

 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}