Multi-Task Learning Using Task Dependencies for Face Attributes Prediction


1
School of Mechatronical Engineering, Beijing Institute of Technology, Beijing 100081, China
2
Beijing Advanced Innovation Center for Intelligent Robots and Systems, Beijing Institute of Technology, Beijing 100081, China
3
School of Electrical Engineering, Korea Advanced Institute of Science and Technology, 291 Daehak-ro, Yuseong-gu, Daejeon 34141, Korea
4
Department of Mechanical and Automation Engineering, The Chinese University of Hong Kong, Shatin, NT, Hong Kong SAR, China
*
Author to whom correspondence should be addressed.
Appl. Sci. 2019, 9(12), 2535; https://doi.org/10.3390/app9122535
Submission received: 21 May 2019
/
Revised: 14 June 2019
/
Accepted: 19 June 2019
/
Published: 21 June 2019
(This article belongs to the Special Issue Computer Vision and Pattern Recognition in the Era of Deep Learning)
Abstract
:Face attributes prediction has an increasing amount of applications in human–computer interaction, face verification and video surveillance. Various studies show that dependencies exist in face attributes. Multi-task learning architecture can build a synergy among the correlated tasks by parameter sharing in the shared layers. However, the dependencies between the tasks have been ignored in the task-specific layers of most multi-task learning architectures. Thus, how to further boost the performance of individual tasks by using task dependencies among face attributes is quite challenging. In this paper, we propose a multi-task learning using task dependencies architecture for face attributes prediction and evaluate the performance with the tasks of smile and gender prediction. The designed attention modules in task-specific layers of our proposed architecture are used for learning task-dependent disentangled representations. The experimental results demonstrate the effectiveness of our proposed network by comparing with the traditional multi-task learning architecture and the state-of-the-art methods on Faces of the world (FotW) and Labeled faces in the wild-a (LFWA) datasets.
1. Introduction
Face attributes are useful to achieve detailed description of human faces (e.g., smile, gender, age, etc.). Face attributes prediction has applications in human–computer interaction, face verification [1,2] and video surveillance [3,4]. Face variations in pose, illumination, scale and occlusion increase the difficulty of face attributes prediction. The performance of face attributes prediction has been improved by using deep convolutional neural networks (DCNNs) [5,6,7,8,9,10]. Face attributes prediction is trained separately in these networks, but the inherent correlation between the face attributes has been ignored.
Various studies show that dependencies exist in face attributes [11,12,13,14,15]. Multi-task learning networks can improve the performance of individual tasks by jointly learning correlated tasks. In traditional multi-task learning architectures, the shared layers learn general representations for all the tasks by parameter sharing while the following task-specific representations are learned in the task-specific layers. However, the dependencies between the tasks have been ignored in the task-specific layers. Accordingly, further improving the performance of individual tasks by using task dependencies among face attributes in the task-specific layers of the multi-task learning architecture is a challenge problem.
We propose a multi-task learning using task dependencies architecture for face attributes prediction and evaluate the performance with the tasks of smile and gender prediction. Our proposed architecture splits into two task-specific branches after the shared layers. In the task-specific branches, we establish the task dependencies in the task-specific layers by incorporating attention mechanism. The fully connected layers in the task-specific layers are transformed by using the designed attention modules for learning task-dependent disentangled representations, where the task-dependent disentangled representations denote the representations [16,17] of one task that are disentangled [18] by depending on another task. The transformed fully connected layers that contain task-dependent disentangled representations are fed into softmax layers to predict the final face attributes. In experiments, we demonstrate the effectiveness of our proposed network by comparing with the traditional multi-task learning architecture and the state-of-the-art methods on FotW and LFWA datasets.
The rest of this paper is organized as follows: Section 2 briefly reviews related works. Section 3 describes the proposed multi-task learning using task dependencies architecture in detail. Section 4 describes the experimental configuration; the results on FotW and LFWA datasets are also presented and discussed in Section 4. Section 5 concludes the paper.
2. Related Work
Multi-task learning. Caruana [19] first analyzed multi-task learning in detail. Since then, multi-task learning has been adopted for solving different computer vision problems. Gkioxari et al. used a convolutional neural network (CNN) for pose prediction and action classification of people in unconstrained images [20]. Eigen et al. proposed a multi-scale convolutional architecture for predicting depth, surface normals and semantic labels [21]. Misra et al. presented cross-stitch units to learn shared representations for multi-task learning in ConvNets [22]. Kokkinos et al. presented a CNN that jointly handles low-, mid-, and high-level vision tasks in a unified architecture [23]. Mallya et al. studied a method for performing multiple tasks in a single deep neural network by iteratively pruning and packing the network parameters [24]. Kim et al. proposed a novel architecture containing multiple networks of different configurations termed deep virtual networks with respect to different tasks and memory budgets [25]. Recently, multi-task learning with DCNNs have also been studied and applied to face attributes prediction. Levi et al. used a deep convolutional neural network(DCNN) for age and gender classification [26]. Liu et al. proposed a novel deep learning framework for attribute prediction in the wild [27]. Ranjan et al. presented a DCNN for face analysis utilizing transfer learning from a face recognition model [28]. Hyun et al. proposed a method to multi-attribute recognition of facial images based on a deep learning network that automatically learns the exclusive and joint relationship among attribute recognition tasks [29]. In multi-task learning, when the prediction of one task which will be used as condition is accurate, other tasks can be formulated by using conditional probability. For example, in [30], the experimental results on the MORPH-II dataset show that the multitask method achieves 98% gender recognition accuracy, thus the age probability can be calculated using the gender-conditioned probability and the marginal gender probability in their proposed conditional multitask learning method. However, the error predicted gender will lead to incorrect calculation of and ; therefore, their method cannot be used when the multitask method cannot predict gender accurately on other datasets.
Attention mechanism. Human perception is similar to the attention mechanism that selects specific parts of the input information, rather than using all input information. In neural networks, attention mechanism can be used as feature selectors that can determine the importance of each feature for the particular task. The attention mechanism has been studied and applied to recurrent neural networks (RNNs) and long short term memory (LSTM) for sequential tasks [31,32,33]. The attention mechanism with DCNNs have been applied to vision-related tasks. Tang et al. proposed a deep-learning based generative framework with visual attention [34]. Xiao et al. applied visual attention to fine-grained classification task using DCNN [35]. Xu et al. presented an attention based model that automatically learns to describe the content of images [36]. Zhao et al. proposed a diversified visual attention network for fine-grained object classification [37]. Inspired by the attention mechanism, we propose a multi-task learning using task dependencies architecture for face attributes prediction in this paper.
The main contributions of this paper are summarized as follows:
- A multi-task learning using task dependencies architecture for face attributes prediction in end-to-end manner. The designed attention modules in our proposed architecture are used for learning task-dependent disentangled representations. We evaluate the performance with the tasks of smile and gender prediction.
- We present experimental results which demonstrate that our proposed architecture outperforms the traditional multi-task learning architecture and show the effectiveness in comparison with the state-of-the-art methods on FotW and LFWA datasets.
3. Proposed Method
3.1. Modeling
Formally, the smile/non-smile prediction of the input face X is defined as . The expected smile/non-smile prediction of the input X is defined as follows:
where is the probability that the smile/non-smile prediction of the input X is s, where . We define S = {‘non-smile’, ‘smile’}.
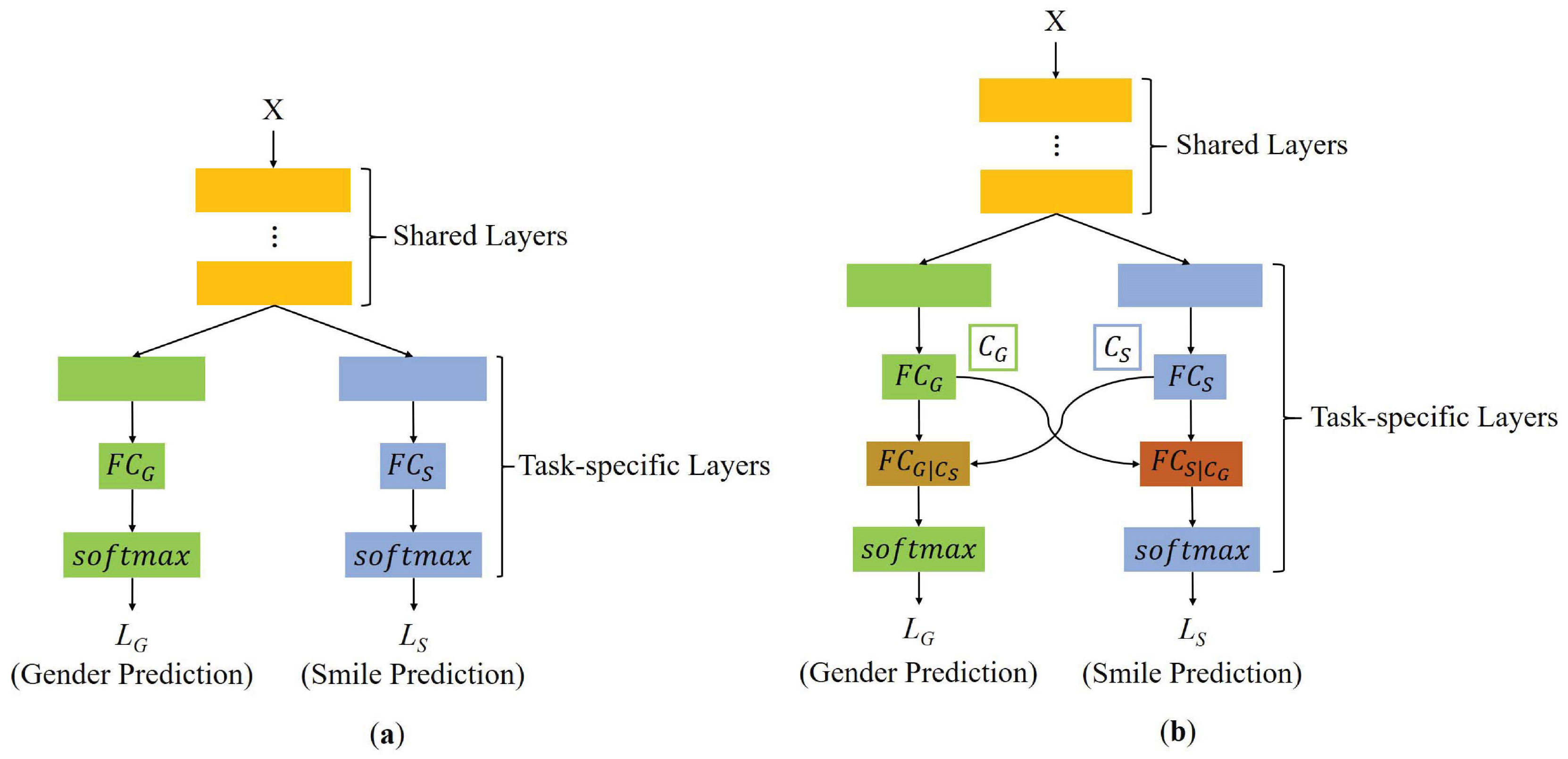
We assume that the predicted smile/non-smile is dependent on the gender of the input X. Compared to the traditional multi-task learning architecture as shown in Figure 1a, the layer has been transformed into layer in the multi-task learning architecture we proposed (shown in Figure 1b). denotes the fully connected layer that contains K() smile/non-smile representation units. denotes the transformed gender dependent fully connected layer that contains K gender dependent smile/non-smile representation units, where is the gender context. We feed the transformed layer into the softmax layer to predict the final smile/non-smile. The probability in Equation (1) can be modeled as follows:
The gender context contains K gender context units , where is the i-th () gender context unit that is automatically chosen from the gender representation units in the layer. denotes the fully connected layer that contains K gender representation units.
The dependency score function that takes a conjunction of the j-th() input smile/non-smile representation unit from the layer and the i-th gender context unit from the layer to score the dependency between and . The dependency score function can be formulated as follows:
The probability reveals the relative importance of based on , where d indicates which input smile/non-smile representation unit in is important based on , where contains K input smile/non-smile representation units. The probability can be calculated using the dependency score function as follows:
The importance probability distribution is defined as follows:
The gender dependent smile/non-smile representation units in the transformed layer can be defined as follows:
where is the i-th () gender dependent smile/non-smile representation unit that is the weighted average of the input smile/non-smile representation units. can be formulated as the expectation of according to the importance probability distribution . The transformed layer is generated by concatenating K gender dependent smile/non-smile representation units.
The gender prediction of the input face X is defined as . The expected gender prediction is defined as follows:
where is the probability that the gender prediction of the input X is g, where . We define G = {‘male’, ‘female’}.
We also assume that the predicted gender is dependent on the smile/non-smile of the input X. The probability in Equation (7) can be modeled as follows:
where denotes the transformed smile/non-smile dependent fully connected layer that contains K smile/non-smile dependent gender representation units, where is the smile/non-smile context chosen from the smile/non-smile representation units in the layer.
The calculation of the smile/non-smile dependent gender representation units in the transformed layer is similar to calculating the gender dependent smile/non-smile representation units in the transformed layer. The smile/non-smile dependent gender representation units can be calculated using Equations (9)–(12) as follows:
3.2. Network Architecture
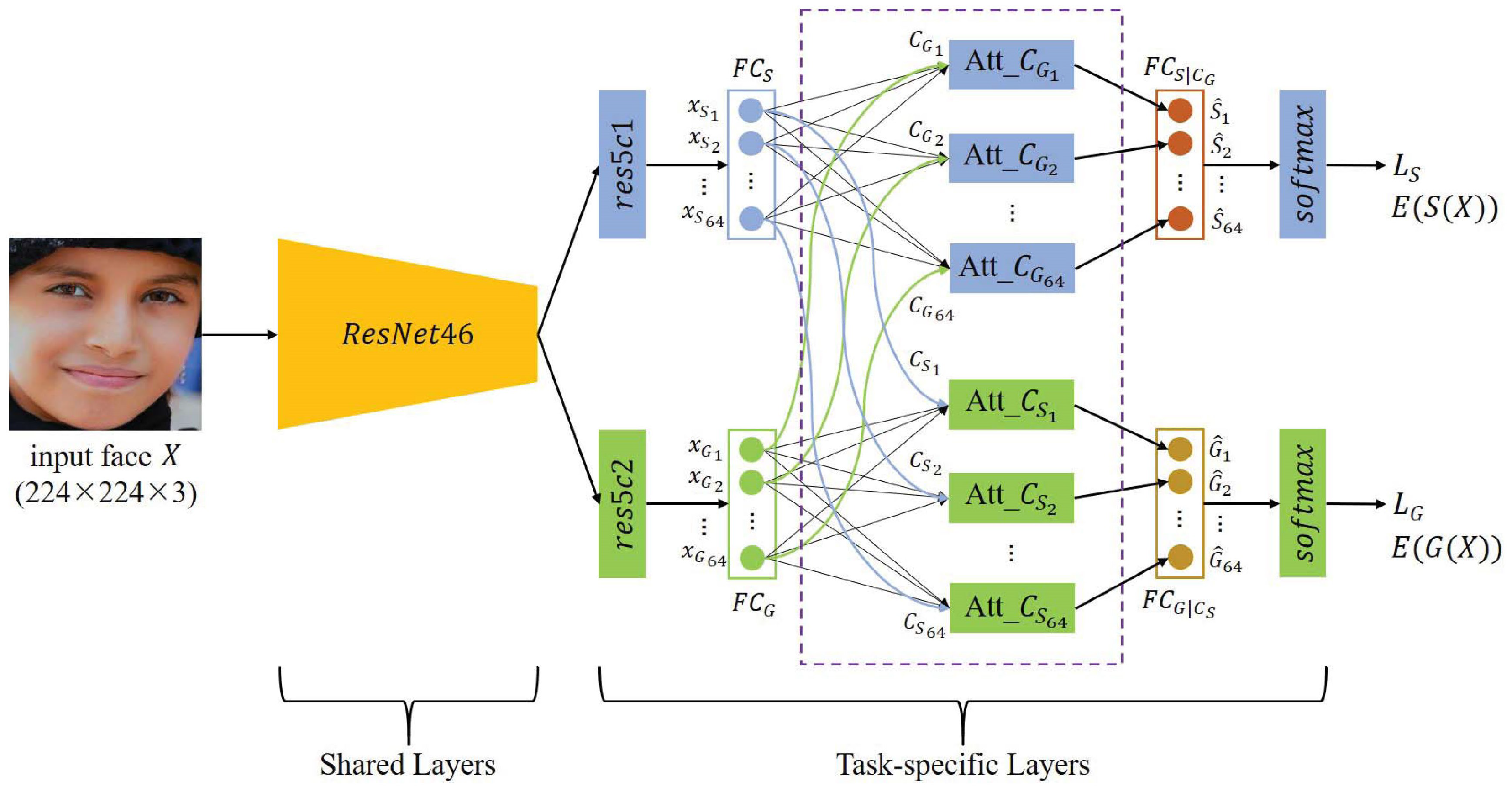
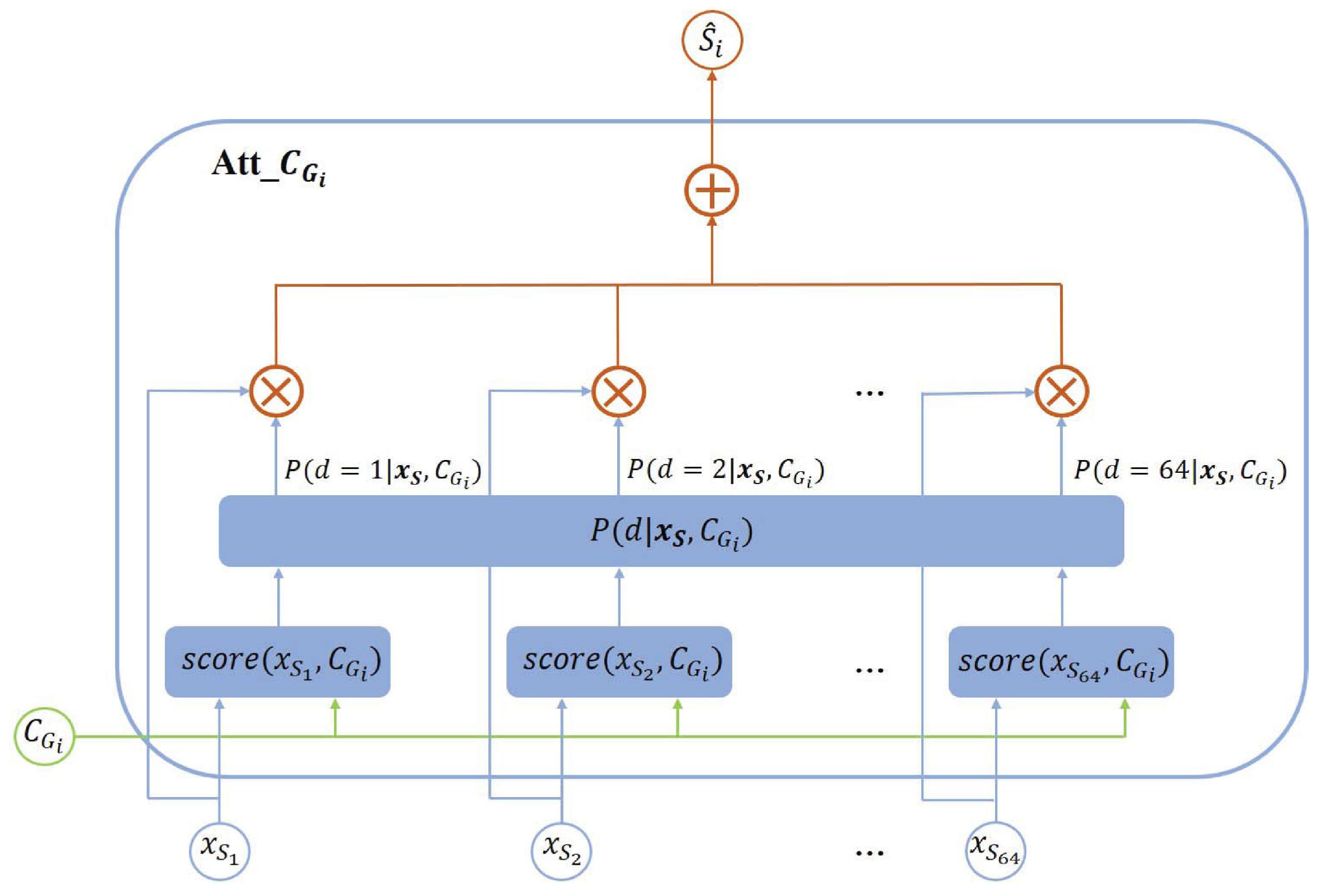
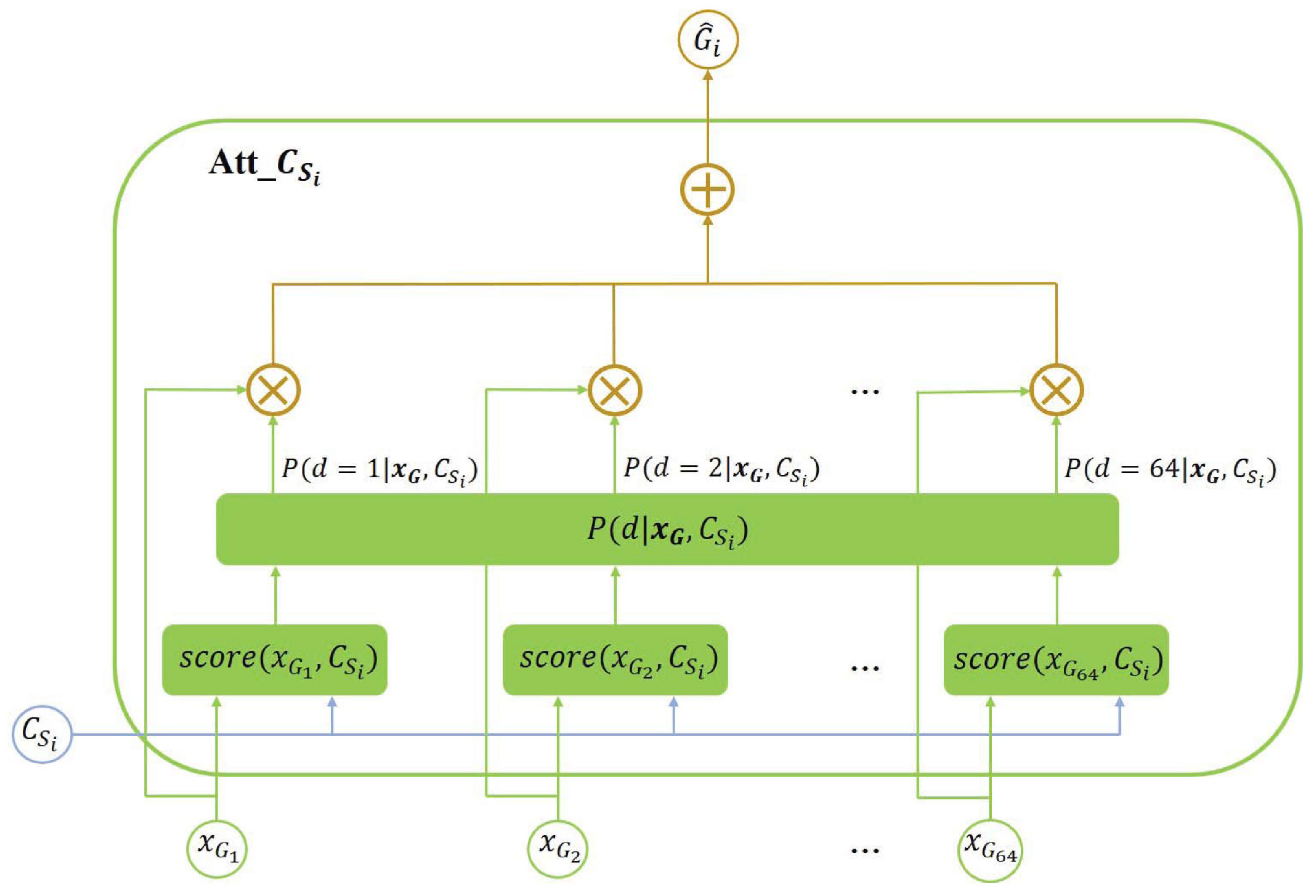
The multi-task learning architecture we proposed is shown in Figure 2. The ResNet50 [38] Network is adapted as the baseline architecture. We share the parameters from its first 46 layers for all the tasks. We evaluate our proposed architecture with the tasks of smile and gender prediction. Thus, the network splits into two task-specific branches corresponding to smile and gender prediction. We attach a fully connected layer that contains 64 smile/non-smile representation units and a fully connected layer that contains 64 gender representation units respectively to ‘res5c1’ and ‘res5c2’, where ‘res5c1’ and ‘res5c2’ are residual blocks in ResNet50. The smile/non-smile representation units in layer and the i-th () gender context unit are fed into the i-th () gender context attention module (shown in Figure 3), where is designed to learn the i-th () gender dependent smile/non-smile representation unit by using Equations (3)–(6). The transformed layer is generated by concatenating 64 gender dependent smile/non-smile representation units. We feed the transformed layer into the softmax layer to predict the final smile/non-smile. The procedure of predicting the final gender is similar to that of predicting the final smile/non-smile in our proposed architecture. The i-th () smile/non-smile context attention module (shown in Figure 4) is designed to learn the i-th () smile/non-smile dependent gender representation unit by using Equations (9)–(12).
3.3. The Model Objective
We use the cross-entropy loss for training the smile prediction task. The loss function is formulated as follows:
where for a smiling face and , otherwise. is the final predicted probability that the input is a smiling face.
We also use the cross-entropy loss for training the gender prediction task. The loss function is formulated as follows:
where if the gender is male and if the gender is female. is the final predicted probability that the input face is a female.
The total loss L is the weighted sum of the individual losses. L is defined as follows:
where and are weight parameters corresponding to smile and gender prediction task, respectively.
4. Experiments
The proposed multi-task learning using task dependencies architecture is evaluated with the tasks of smile and gender prediction. The architecture in which we feed and layers directly into softmax layers to predict the final smile/non-smile and gender respectively as shown in Figure 1a is called TMTL (Traditional Multi Task Learning). We select TMTL architecture as the comparison baseline.
4.1. Datasets
We evaluate the smile and gender prediction performance on Faces of the World (FotW) [39] and Labeled Faces in the Wild-a (LFWA) [40] datasets. Both FotW and LFWA datasets cover large variations in pose, illumination and scale of faces. The FotW dataset contains 9130 images, each of which is labeled with non-smile/smile and male/female. The FotW dataset has been split into 6078 images for training and 3052 images for validation. The LFWA dataset contains 13,143 images, each of which is labeled with non-smile/smile, male/female and thirty-eight other face attributes. The LFWA dataset has been split into 6263 images for training and 6880 images for validation.
4.2. Experimental Configuration
For the FotW dataset, we crop the faces from the original images using the provided coordinates of the bounding box and resize the cropped face images to . For the LFWA dataset, we directly resize the face images to .
All the architectures are trained using the keras [41] framework. Data augmentation such as horizontal flip, horizontal shift and vertical shift are adopted to prevent overfitting. We train all the architectures using Adam with a mini-batch size of 64. The initial learning rate is set to 0.001. The learning rate will decrease to 0.0001 after training 25 epochs. The weight parameters are decided based on the importance of the task in the overall loss. We assume that the smile prediction task and the gender prediction task have the same importance in our proposed architecture due to both of the tasks being binary classification problems. Therefore, we set the weight parameters , . For FotW dataset and LFWA datasets, we adopt he_normal as the weight initialization method and train TMTL architecture 40 epochs (overfitting after 40 epochs) and 30 epochs (overfitting after 30 epochs), respectively. For all the datasets, we initialize our proposed architecture with trained weights from TMTL architecture and train 30 epochs, respectively.
4.3. The Effectiveness of Multi-Task Learning Using Task Dependencies
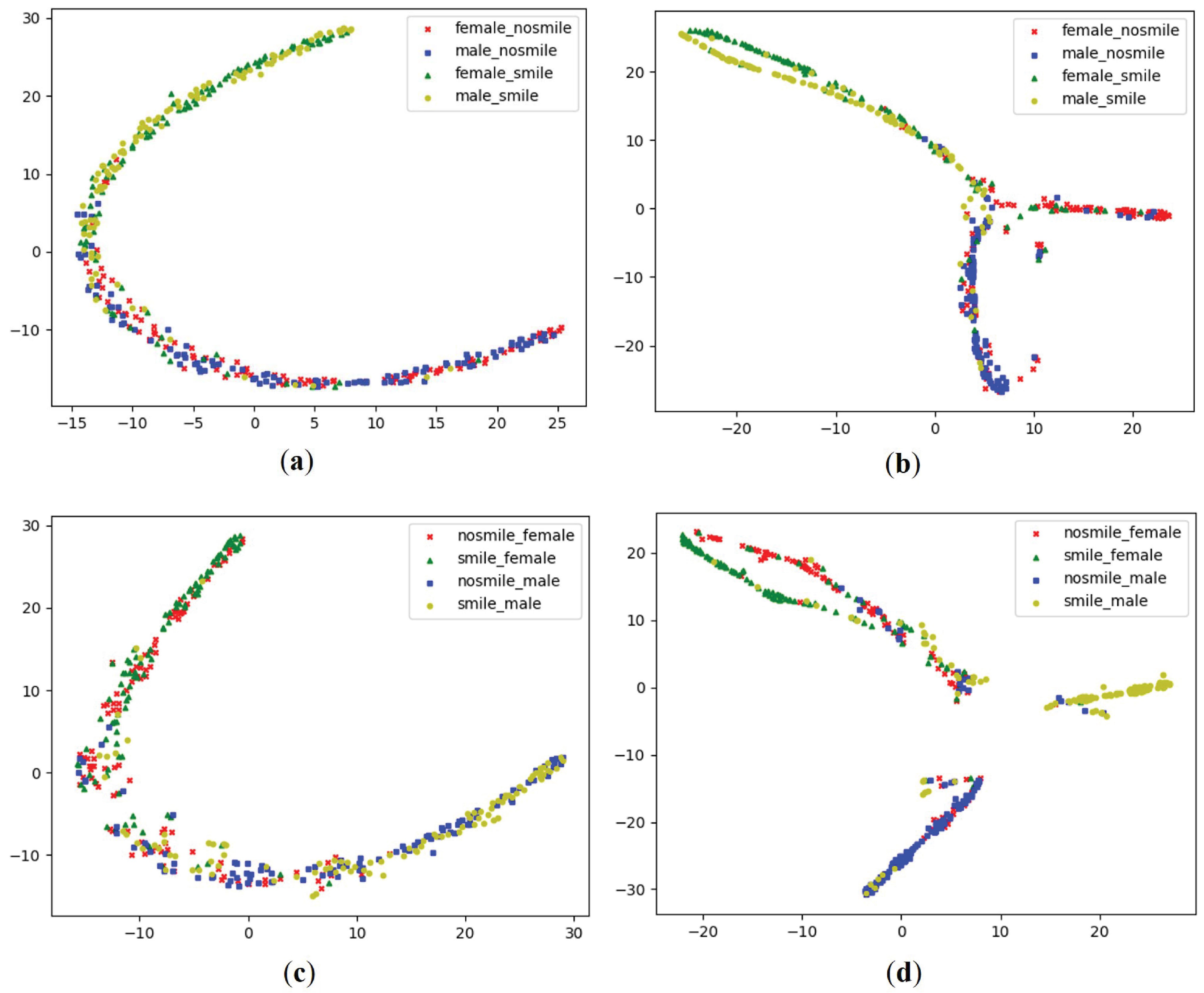
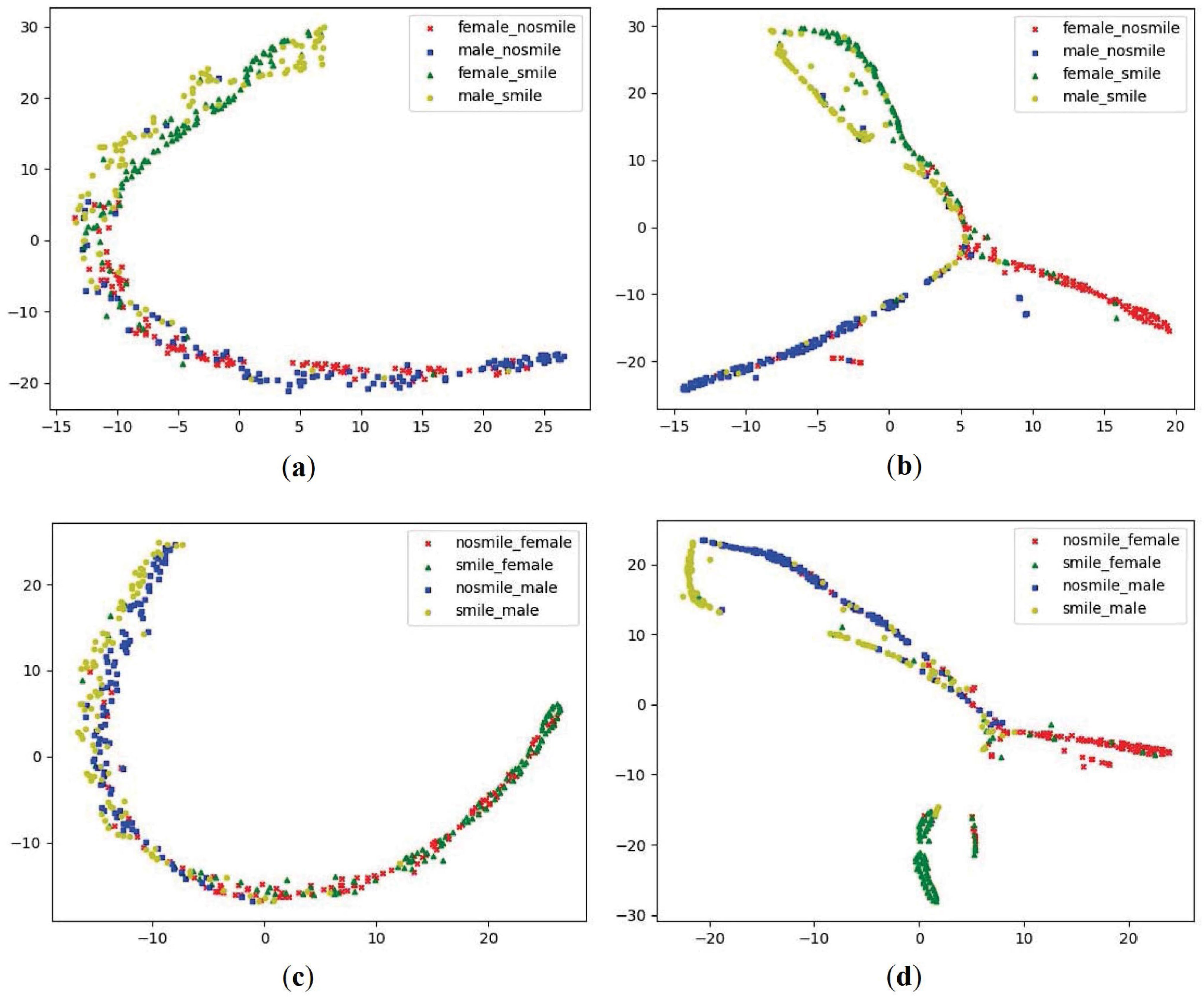
We evaluate the contribution of multi-task learning using task dependencies. Disentangling the underlying structure of representations into disjoint parts can benefit for solving a diverse set of tasks in a data-efficient manner. The disentangled representations are vector representations with respect to a particular decomposition of a group into subgroups using the group and representation theory [42]. Table 1 shows that our proposed architecture in comparison with TMTL architecture on FotW and LFWA datasets, respectively. Our proposed architecture produces performance gains over TMTL architecture because our proposed architecture disentangles smile/non-smile and gender representations into gender dependent smile/non-smile and smile/non-smile dependent gender representations, respectively, by establishing the task dependencies between smile and gender prediction tasks in the task-specific layers. We combine (smile/non-smile × gender) into four groups. For each of the groups, we randomly sample 100 images from the FotW validation dataset. The t-distributed stochastic neighbor embedding (t-SNE) [43] on the sampled FotW validation dataset show the distributions of the representations in and layers, respectively, in Figure 5a,c, and show the distributions of the gender dependent smile/nonsmile and smile/non-smile dependent gender representations in and layers, respectively, in Figure 5b,d. Clusters in Figure 5b,d are disentangled by gender and smile/non-smile more explicitly compared to those in Figure 5a,c. The procedure of achieving the sampled LFWA validation dataset is the same as that of achieving the sampled FotW validation dataset. The t-SNE on the sampled LFWA validation dataset shows the distributions of the representations in and layers, respectively, in Figure 6a,c, and show the distributions of the gender dependent smile/nonsmile and smile/non-smile dependent gender representations in and layers, respectively, in Figure 6b,d. Clusters in Figure 6b,d are also disentangled by gender and smile/non-smile more explicitly compared to those in Figure 6a,c.
4.4. Comparison with Previous Approaches
We initialize our proposed architecture using the weights from ResNet50 pre-trained on ImageNet [44]. Table 2 and Table 3 compare our results with those of previous methods on FotW and LFWA datasets, respectively. Our average accuracy is lower than SIAT_MMLAB on the FotW dataset and LNets+ANet on the LFWA dataset. The SIAT_MMLAB architecture is composed of GNet for gender classification and two SNets for smile classification. GNet and two SNets are trained with different face cropping schemes for better performance. The SIAT_MMLAB architecture adopts the VGG-Faces [45] model, which is pre-trained on a large-scale face identification dataset for face identification and face verification. They use a general-to-specific fine-tuning scheme that fine-tunes the model three times on CelebA [27] (with forty attribute annotations), CelebA (with smile and gender annotations) and FotW (with smile and gender annotations) datasets, respectively. The LNets+ANet architecture integrates two CNNs LNet and ANet, where LNet locates the entire face region and ANet extracts features for attribute recognition. LNet is pre-trained on ImageNet and fine-tuned by image-level attribute tags. ANet is pre-trained on the CelebA dataset and fine-tuned by attribute tags. Our proposed architecture can perform smile and gender prediction tasks in the end-to-end manner using a single deep neural network. The input face images are processed as mentioned in experimental configurations with no extra face cropping and localization steps. We only use the weights from ResNet50 pre-trained on ImageNet for weight initialization. The results also show the effectiveness of our proposed architecture in comparison with previous state-of-the-art methods.
5. Conclusions
In this paper, we have proposed a novel multi-task learning using task dependencies architecture for face attributes prediction and evaluated the performance with the tasks of smile and gender prediction. We transformed the fully connected layers by using the designed attention modules for learning task-dependent disentangled representations. The transformed fully connected layers were fed into softmax layers to predict the final face attributes. The experimental results demonstrate the effectiveness of our proposed network by comparing with the traditional multi-task learning architecture and the state-of-the-art methods on FotW and LFWA datasets. In the future, we will evaluate the performance of our proposed architecture with more tasks of face attributes prediction. We also plan to apply the attention module to more fully connected layers or convolution layers and try to use dynamic weights for performing more face attributes’ prediction tasks.
Author Contributions
Conceptualization, D.F. and H.K.; methodology, D.F. and H.K.; software, D.F.; formal analysis, J.K.; writing—original draft preparation, D.F. and Y.L.; writing—review and editing, H.K., J.K. and H.Q.; visualization, Y.L.; funding acquisition, H.Q.
Funding
This work was supported by the National Natural Science Foundation of China (Grant No. 91748202).
Conflicts of Interest
The authors declare that they have no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| DCNNs | Deep convolutional neural networks |
| CNN | Convolutional neural networks |
| DCNN | Deep convolutional neural network |
| RNNs | Recurrent neural networks |
| LSTM | Long short term memory |
| TMTL | Traditional multi task learning |
| FotW | Faces of the world |
| LFWA | Labeled faces in the wild-a |
| t-SNE | T-distributed stochastic neighbor embedding |
References
- Kumar, N.; Berg, A.C.; Belhumeur, P.N.; Nayar, S.K. Attribute and simile classifiers for face verification. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 365–372. [Google Scholar]
- Song, F.; Tan, X.; Chen, S. Exploiting relationship between attributes for improved face verification. Comput. Vis. Image Underst. 2014, 122, 143–154. [Google Scholar] [CrossRef]
- Vaquero, D.A.; Feris, R.S.; Tran, D.; Brown, L.; Hampapur, A.; Turk, M. Attribute-based people search in surveillance environments. In Proceedings of the 2009 Workshop on Applications of Computer Vision (WACV), Snowbird, UT, USA, 7–8 December 2009; pp. 1–8. [Google Scholar]
- Li, D.; Chen, X.; Huang, K. Multi-attribute learning for pedestrian attribute recognition in surveillance scenarios. In Proceedings of the 2015 3rd IAPR Asian Conference on Pattern Recognition (ACPR), Kuala Lumpur, Malaysia, 3–6 November 2015; pp. 111–115. [Google Scholar]
- Glauner, P.O. Deep convolutional neural networks for smile recognition. arXiv 2015, arXiv:1508.06535. [Google Scholar]
- Chen, J.; Ou, Q.; Chi, Z.; Fu, H. Smile detection in the wild with deep convolutional neural networks. Mach. Vis. Appl. 2017, 28, 173–183. [Google Scholar] [CrossRef]
- Nian, F.; Li, L.; Li, T.; Xu, C. Robust gender classification on unconstrained face images. In Proceedings of the 7th International Conference on Internet Multimedia Computing and Service, Zhangjiajie City, China, 19–21 August 2015; p. 77. [Google Scholar]
- Mansanet, J.; Albiol, A.; Paredes, R. Local deep neural networks for gender recognition. Pattern Recognit. Lett. 2016, 70, 80–86. [Google Scholar] [CrossRef]
- Rothe, R.; Timofte, R.; van Gool, L. Dex: Deep expectation of apparent age from a single image. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Santiago, Chile, 7–13 December 2015; pp. 10–15. [Google Scholar]
- Liu, X.; Li, S.; Kan, M.; Zhang, J.; Wu, S.; Liu, W.; Han, H.; Shan, S.; Chen, X. Agenet: Deeply learned regressor and classifier for robust apparent age estimation. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Santiago, Chile, 7–13 December 2015; pp. 16–24. [Google Scholar]
- Brody, L.R.; Hall, J.A. Gender and emotion in context. Handb. Emot. 2008, 3, 395–408. [Google Scholar]
- Bilinski, P.; Dantcheva, A.; Brémond, F. Can a smile reveal your gender? In Proceedings of the 2016 International Conference of the Biometrics Special Interest Group (BIOSIG), Darmstadt, Germany, 21–23 September 2016; pp. 1–6. [Google Scholar]
- Dantcheva, A.; Brémond, F. Gender estimation based on smile-dynamics. IEEE Trans. Inf. Forensics Secur. 2017, 12, 719–729. [Google Scholar] [CrossRef]
- Desai, S.; Upadhyay, M.; Nanda, R. Dynamic smile analysis: Changes with age. Am. J. Orthod. Dentofac. Orthop. 2009, 136, 310. [Google Scholar] [CrossRef]
- Guo, G.; Dyer, C.R.; Fu, Y.; Huang, T.S. Is gender recognition affected by age? In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision Workshops, ICCV Workshops, Kyoto, Japan, 27 September–4 October 2009; pp. 2032–2039. [Google Scholar]
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef]
- He, R.; Wu, X.; Sun, Z.; Tan, T. Learning invariant deep representation for nir-vis face recognition. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Rifai, S.; Bengio, Y.; Courville, A.; Vincent, P.; Mirza, M. Disentangling factors of variation for facial expression recognition. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2012; pp. 808–822. [Google Scholar]
- Caruana, R. Multitask learning. Mach. Learn. 1997, 28, 41–75. [Google Scholar] [CrossRef]
- Gkioxari, G.; Hariharan, B.; Girshick, R.; Malik, J. R-cnns for pose estimation and action detection. arXiv 2014, arXiv:1406.5212. [Google Scholar]
- Eigen, D.; Fergus, R. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 2650–2658. [Google Scholar]
- Misra, I.; Shrivastava, A.; Gupta, A.; Hebert, M. Cross-stitch networks for multi-task learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 3994–4003. [Google Scholar]
- Kokkinos, I. Ubernet: Training a universal convolutional neural network for low-, mid-, and high-level vision using diverse datasets and limited memory. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6129–6138. [Google Scholar]
- Mallya, A.; Lazebnik, S. Packnet: Adding multiple tasks to a single network by iterative pruning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7765–7773. [Google Scholar]
- Kim, E.; Ahn, C.; Torr, P.H.; Oh, S. Deep virtual networks for memory efficient inference of multiple tasks. arXiv 2019, arXiv:1904.04562. [Google Scholar]
- Levi, G.; Hassner, T. Age and gender classification using convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015; pp. 34–42. [Google Scholar]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep learning face attributes in the wild. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 3730–3738. [Google Scholar]
- Ranjan, R.; Sankaranarayanan, S.; Castillo, C.D.; Chellappa, R. An all-in-one convolutional neural network for face analysis. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017; pp. 17–24. [Google Scholar]
- Hyun, C.; Seo, J.; Lee, K.E.; Park, H. Multi-attribute recognition of facial images considering exclusive and correlated relationship among attributes. Appl. Sci. 2019, 9, 2034. [Google Scholar] [CrossRef]
- Yoo, B.; Kwak, Y.; Kim, Y.; Choi, C.; Kim, J. Deep facial age estimation using conditional multitask learning with weak label expansion. IEEE Signal Process. Lett. 2018, 25, 808–812. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Luong, M.-T.; Pham, H.; Manning, C.D. Effective approaches to attention-based neural machine translation. arXiv 2015, arXiv:1508.04025. [Google Scholar]
- Yang, Z.; Hu, Z.; Deng, Y.; Dyer, C.; Smola, A. Neural machine translation with recurrent attention modeling. arXiv 2016, arXiv:1607.05108. [Google Scholar]
- Tang, Y.; Srivastava, N.; Salakhutdinov, R.R. Learning generative models with visual attention. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 1808–1816. [Google Scholar]
- Xiao, T.; Xu, Y.; Yang, K.; Zhang, J.; Peng, Y.; Zhang, Z. The application of two-level attention models in deep convolutional neural network for fine-grained image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 842–850. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 6 2015; pp. 2048–2057. [Google Scholar]
- Zhao, B.; Wu, X.; Feng, J.; Peng, Q.; Yan, S. Diversified visual attention networks for fine-grained object classification. IEEE Trans. Multimedia 2017, 19, 1245–1256. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Escalera, S.; Torres, M.T.; Martinez, B.; Baró, X.; Escalante, H.J.; Guyon, I.; Tzimiropoulos, G.; Corneou, C.; Oliu, M.; Bagheri, M.A.; et al. Chalearn looking at people and faces of the world: Face analysis workshop and challenge 2016. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1–8. [Google Scholar]
- Huang, G.B.; Mattar, M.; Berg, T.; Learned-Miller, E. Labeled faces in the wild: A database forstudying face recognition in unconstrained environments. In Proceedings of the Workshop on faces in’Real-Life’Images: Detection, Alignment, and Recognition, Marseille, France, 17–20 October 2008. [Google Scholar]
- Chollet, F. Keras. 2015. Available online: https://github.com/keras-team/keras (accessed on 1 March 2018).
- Higgins, I.; Amos, D.; Pfau, D.; Racaniere, S.; Matthey, L.; Rezende, D.; Lerchner, A. Towards a definition of disentangled representations. arXiv 2018, arXiv:1812.02230. [Google Scholar]
- Maaten, L.V.D.; Hinton, G. Visualizing data using t-sne. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Li, F.-F. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A. Deep face recognition. BMVC 2015, 1, 6. [Google Scholar]
- Han, H.; Jain, A.K.; Wang, F.; Shan, S.; Chen, X. Heterogeneous face attribute estimation: A deep multi-task learning approach. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 2597–2609. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Kang, Q.; Ge, G.; Song, Q.; Lu, H.; Cheng, J. Deepbe: Learning deep binary encoding for multi-label classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 39–46. [Google Scholar]
- Zhang, K.; Tan, L.; Li, Z.; Qiao, Y. Gender and smile classification using deep convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 34–38. [Google Scholar]
- Zhang, N.; Paluri, M.; Ranzato, M.; Darrell, T.; Bourdev, L. Panda: Pose aligned networks for deep attribute modeling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1637–1644. [Google Scholar]
- Zhuang, N.; Yan, Y.; Chen, S.; Wang, H. Multi-task learning of cascaded cnn for facial attribute classification. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 2069–2074. [Google Scholar]
- Zhuang, N.; Yan, Y.; Chen, S.; Wang, H.; Shen, C. Multi-label learning based deep transfer neural network for facial attribute classification. Pattern Recognit. 2018, 80, 225–240. [Google Scholar] [CrossRef] [Green Version]
Figure 1.
Comparison of traditional multi-task learning and our proposed multi-task learning architecture. (a) traditional multi-task learning; (b) our proposed multi-task learning.
Figure 1.
Comparison of traditional multi-task learning and our proposed multi-task learning architecture. (a) traditional multi-task learning; (b) our proposed multi-task learning.

Figure 2.
The architecture of the proposed multi-task learning convolutional neural network.

Figure 3.
The designed gender context attention module.

Figure 4.
The designed smile/non-smile context attention module.

Figure 5.
t-SNE visulization on the sampled FotW validation dataset. (a) t-SNE visualization of ; (b) t-SNE visualization of ; (c) t-SNE visualization of ; (d) t-SNE visualization of .
Figure 5.
t-SNE visulization on the sampled FotW validation dataset. (a) t-SNE visualization of ; (b) t-SNE visualization of ; (c) t-SNE visualization of ; (d) t-SNE visualization of .

Figure 6.
t-SNE visulization on the sampled LFWA validation dataset. (a) t-SNE visulization of ; (b) t-SNE visualization of ; (c) t-SNE visualization of ; (d) t-SNE visualization of .
Figure 6.
t-SNE visulization on the sampled LFWA validation dataset. (a) t-SNE visulization of ; (b) t-SNE visualization of ; (c) t-SNE visualization of ; (d) t-SNE visualization of .


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Comparison results for smile and gender prediction on the FotW dataset and the LFWA dataset.
Table 1.
Comparison results for smile and gender prediction on the FotW dataset and the LFWA dataset.
| Dataset | Architecture | Smile | Gender |
|---|---|---|---|
| FotW | TMTL | 86.83% | 82.54% |
| Ours | 88.53% | 84.83% | |
| LFWA | TMTL | 90.74% | 91.80% |
| Ours | 91.13% | 92.49% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Fan, D.; Kim, H.; Kim, J.; Liu, Y.; Huang, Q. Multi-Task Learning Using Task Dependencies for Face Attributes Prediction. Appl. Sci. 2019, 9, 2535. https://doi.org/10.3390/app9122535
AMA Style
Fan D, Kim H, Kim J, Liu Y, Huang Q. Multi-Task Learning Using Task Dependencies for Face Attributes Prediction. Applied Sciences. 2019; 9(12):2535. https://doi.org/10.3390/app9122535
Chicago/Turabian StyleFan, Di, Hyunwoo Kim, Junmo Kim, Yunhui Liu, and Qiang Huang. 2019. "Multi-Task Learning Using Task Dependencies for Face Attributes Prediction" Applied Sciences 9, no. 12: 2535. https://doi.org/10.3390/app9122535
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.